
Разработка ИИ-решений для бизнеса требует системного подхода к архитектуре и глубокого понимания корпоративной инфраструктуры. От правильного выбора технического стека и архитектурных паттернов зависит масштабируемость, производительность и стоимость поддержки ИИ-системы. В этой статье разберем проверенные подходы к проектированию корпоративных ИИ-решений.
Базовая архитектура ИИ-систем для бизнеса
Многослойная модель ИИ-приложения:
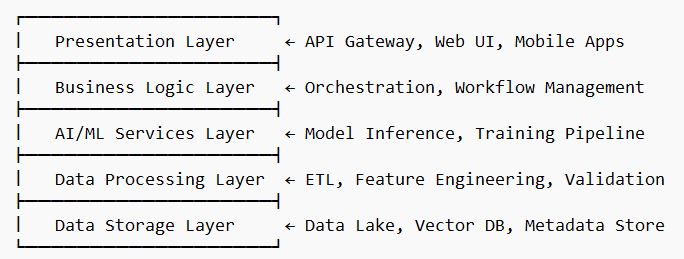
Ключевые компоненты архитектуры:
1. Слой представления (Presentation Layer)
- API Gateway — единая точка входа для всех запросов
- Web Dashboard — интерфейс для бизнес-пользователей
- REST/GraphQL API — интеграция с внешними системами
- Webhooks — уведомления о событиях в реальном времени
2. Слой бизнес-логики (Business Logic Layer)
- Workflow Engine — оркестрация ИИ-процессов (Apache Airflow)
- Business Rules Engine — валидация и фильтрация данных
- Authentication/Authorization — управление доступом (OAuth 2.0, JWT)
- Audit & Logging — трекинг всех операций для compliance
3. Слой ИИ-сервисов (AI/ML Services Layer)
- Model Serving — inference API (TensorFlow Serving, Triton)
- Model Registry — версионирование моделей (MLflow, DVC)
- AutoML Pipeline — автоматическое обучение моделей
- A/B Testing Framework — тестирование моделей в продакшене
Технологический стек для корпоративных ИИ-решений
Серверная инфраструктура:
# Основной стек
Python 3.9+ / Node.js 18+
FastAPI / Express.js / Spring Boot
Docker + Kubernetes
Redis / PostgreSQL / MongoDB# ИИ/ML компоненты
TensorFlow / PyTorch / scikit-learn
Hugging Face Transformers
LangChain / LlamaIndex (для LLM)
Apache Spark / Dask (для больших данных)
Облако & DevOps:
- Контейнеризация: Docker, Kubernetes, Helm charts
- CI/CD: GitLab CI, GitHub Actions, ArgoCD
- Мониторинг: Prometheus, Grafana, ELK Stack
- Cloud Providers: AWS SageMaker, Google AI Platform, Azure ML
Рекомендуемый ML-стек по задачам:
| Задача | Технология | Обоснование |
|---|---|---|
| NLP/Чат-боты | Hugging Face + FastAPI | Готовые модели, быстрый inference |
| Computer Vision | YOLOv8 + OpenCV | Высокая точность, GPU-оптимизация |
| Предиктивная аналитика | XGBoost + Optuna | Отличное качество на табличных данных |
| Рекомендательные системы | PyTorch + Apache Spark | Масштабируемость для больших данных |
Интеграция с корпоративными системами
Паттерны интеграции:
1. Event-Driven Architecture (EDA)
# Пример с Apache Kafka
from kafka import KafkaProducer, KafkaConsumer# Producer (CRM отправляет событие о новом лиде)
producer = KafkaProducer(
bootstrap_servers=['kafka:9092'],
value_serializer=lambda x: json.dumps(x).encode('utf-8')
)producer.send('lead_events', {
'lead_id': 12345,
'source': 'website',
'timestamp': datetime.now().isoformat()
})# Consumer (ИИ-система обрабатывает лид)
consumer = KafkaConsumer('lead_events')
for message in consumer:
lead_data = json.loads(message.value)
ai_score = calculate_lead_score(lead_data)
update_crm_with_score(lead_data['lead_id'], ai_score)
2. API-First подход
# FastAPI с автогенерацией OpenAPI схемы
from fastapi import FastAPI, HTTPException
from pydantic import BaseModelapp = FastAPI(title="AI Scoring Service")
class LeadData(BaseModel):
company_size: int
industry: str
budget: float
urgency: str@app.post("/api/v1/score-lead")
async def score_lead(lead: LeadData):
try:
score = ai_model.predict(lead.dict())
return {
"lead_score": float(score),
"confidence": 0.85,
"next_action": "contact_immediately" if score > 0.7 else "nurture"
}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
Стандартные интеграции:
CRM системы (Salesforce, HubSpot):
- REST API для обновления лидов и сделок
- Webhooks для получения событий в реальном времени
- Bulk API для массовой обработки данных
ERP системы (1С, SAP):
- SOAP/REST адаптеры для обмена финансовыми данными
- ODBC/JDBC подключения к базам данных
- File-based integration через CSV/XML файлы
Системы коммуникаций:
- Slack/Teams боты для уведомлений
- Email API (SendGrid, Mailgun) для автоматической рассылки
- SMS-шлюзы для критичных уведомлений
Управление данными и безопасность
Data Pipeline архитектура:
# Apache Airflow DAG для обработки данных
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedeltadef extract_crm_data(**context):
# Извлечение данных из CRM
data = fetch_from_salesforce_api()
return datadef transform_for_ml(**context):
# Feature engineering
raw_data = context['task_instance'].xcom_pull(task_ids='extract')
features = create_ml_features(raw_data)
return featuresdef train_model(**context):
# Переобучение модели
features = context['task_instance'].xcom_pull(task_ids='transform')
model = retrain_ai_model(features)
save_model_to_registry(model)dag = DAG(
'ml_pipeline',
schedule_interval='@daily',
start_date=datetime(2024, 1, 1)
)extract_task = PythonOperator(
task_id='extract',
python_callable=extract_crm_data,
dag=dag
)transform_task = PythonOperator(
task_id='transform',
python_callable=transform_for_ml,
dag=dag
)train_task = PythonOperator(
task_id='train',
python_callable=train_model,
dag=dag
)extract_task >> transform_task >> train_task
Безопасность ИИ-систем:
Аутентификация и авторизация:
- OAuth 2.0 + JWT для API доступа
- RBAC (Role-Based Access Control) для разных уровней доступа
- API Rate Limiting для защиты от DDoS
Защита данных:
- Шифрование в покое (AES-256) для чувствительных данных
- TLS 1.3 для всех сетевых соединений
- Data masking для тестовых сред
Соответствие регулированию:
# Пример GDPR-compliant логирования
import logging
from datetime import datetimeclass GDPRCompliantLogger:
def __init__(self):
self.logger = logging.getLogger('ai_system')
def log_ai_decision(self, user_id: str, decision: dict,
explanation: str):
log_entry = {
'timestamp': datetime.utcnow().isoformat(),
'user_id': self.hash_user_id(user_id), # Псевдонимизация
'decision': decision,
'explanation': explanation,
'model_version': self.get_model_version()
}
self.logger.info(json.dumps(log_entry, ensure_ascii=False))
Мониторинг и observability
Ключевые метрики для мониторинга:
Бизнес-метрики:
- Model Accuracy — точность предсказаний модели
- Inference Latency — время отклика API (< 200ms)
- Throughput — количество запросов в секунду
- Business KPI Impact — влияние на бизнес-показатели
Технические метрики:
# Prometheus метрики для ИИ-сервиса
from prometheus_client import Counter, Histogram, start_http_server# Счетчики запросов
request_count = Counter('ai_requests_total', 'Total AI requests')
error_count = Counter('ai_errors_total', 'Total AI errors')# Гистограмма времени выполнения
request_duration = Histogram('ai_request_duration_seconds',
'AI request duration')@request_duration.time()
def predict_with_monitoring(data):
request_count.inc()
try:
prediction = ai_model.predict(data)
return prediction
except Exception as e:
error_count.inc()
raise e
Data Drift Detection:
# Мониторинг drift с использованием evidently
from evidently import ColumnMapping
from evidently.report import Report
from evidently.metric_preset import DataDriftPresetdef check_data_drift(reference_data, current_data):
report = Report(metrics=[DataDriftPreset()])
report.run(reference_data=reference_data,
current_data=current_data)
drift_score = report.as_dict()['metrics'][0]['result']['drift_score']
if drift_score > 0.1: # Порог drift
send_alert_to_team("Data drift detected!", drift_score)
trigger_model_retraining()
Оптимизация производительности
Стратегии масштабирования:
Model Serving оптимизация:
- Model Quantization — сжатие моделей без потери качества
- Batch Inference — обработка запросов батчами
- Model Caching — кеширование популярных предсказаний
- GPU Optimization — использование TensorRT, ONNX Runtime
Horizontal Scaling:
# Kubernetes Deployment для ИИ-сервиса
apiVersion: apps/v1
kind: Deployment
metadata:
name: ai-inference-service
spec:
replicas: 3 # Автомасштабирование по нагрузке
selector:
matchLabels:
app: ai-inference
template:
metadata:
labels:
app: ai-inference
spec:
containers:
- name: ai-service
image: ai-service:latest
resources:
requests:
memory: "2Gi"
cpu: "1000m"
limits:
memory: "4Gi"
cpu: "2000m"
env:
- name: MODEL_PATH
value: "/models/production"
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: ai-service-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ai-inference-service
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
Лучшие практики разработки
1. MLOps Pipeline:
- Version Control для кода, данных и моделей (Git + DVC)
- Continuous Training — автоматическое переобучение при деградации
- Model A/B Testing — сравнение моделей в production
- Rollback Strategy — быстрый откат к предыдущей версии
2. Code Quality:
# Пример типизированного ИИ-сервиса
from typing import List, Optional, Dict, Any
from pydantic import BaseModel, validator
import pytestclass PredictionRequest(BaseModel):
features: Dict[str, Any]
model_version: Optional[str] = "latest"
@validator('features')
def validate_features(cls, v):
required_fields = ['age', 'income', 'score']
for field in required_fields:
if field not in v:
raise ValueError(f"Missing required field: {field}")
return vclass AIService:
def __init__(self, model_registry: ModelRegistry):
self.model_registry = model_registry
def predict(self, request: PredictionRequest) -> Dict[str, Any]:
model = self.model_registry.get_model(request.model_version)
prediction = model.predict(request.features)
return {
"prediction": prediction,
"confidence": float(model.predict_proba(request.features).max()),
"model_version": request.model_version
}# Unit тесты
def test_prediction_service():
service = AIService(mock_model_registry)
request = PredictionRequest(
features={"age": 30, "income": 50000, "score": 0.8}
)
result = service.predict(request)
assert "prediction" in result
assert 0 <= result["confidence"] <= 1
assert result["model_version"] == "latest"
3. Документация:
- API Documentation — автогенерация с помощью OpenAPI
- Model Cards — описание возможностей и ограничений моделей
- Architecture Decision Records (ADR) — документирование архитектурных решений
- Runbooks — инструкции для операционной поддержки
Типичные архитектурные ошибки
❌ Монолитная архитектура — сложно масштабировать и поддерживать
❌ Отсутствие версионирования моделей — невозможно откатиться
❌ Синхронные вызовы для тяжелых ML-задач — блокировка UI
❌ Игнорирование security — уязвимости в production
❌ Отсутствие мониторинга model drift — деградация качества
Чек-лист архитектурной готовности
✅ Определена multi-tier архитектура с четким разделением слоев
✅ Выбран подходящий tech stack для конкретных ML-задач
✅ Спроектированы API для интеграции с корпоративными системами
✅ Настроены CI/CD pipeline для автоматического деплоя
✅ Реализован comprehensive мониторинг всех компонентов
✅ Обеспечена data security и соответствие регулированию
Архитектура ИИ-решений для бизнеса должна быть масштабируемой, безопасной и maintainable. Правильный выбор технологического стека и архитектурных паттернов на раннем этапе поможет избежать технического долга и обеспечит долгосрочную поддерживаемость системы.
Начинайте с MVP-архитектуры, постепенно добавляя сложность по мере роста требований. Инвестируйте в мониторинг и observability с самого начала — это окупится при первом же инциденте в production.